threading多线程模块
基本使用
Python中提供了threading模块用来实现线程并发编程,使用方法有两种,一种是将threading模块下的Therad类进行实例化的方式实现,一种是通过继承threading模块下的Therad类并覆写run()方法实现。
实例化Therad类创建子线程
这种方式是最常用的也是推荐使用的方式。先来介绍一个Therad类中的方法,然后再看代码。
start():开始线程活动。它在一个线程里最多只能被调用一次。它安排对象的
PS:该方法不会立即执行,只是告诉CPU说你可以调度我了,我准备好了,一定要注意不是立即执行!
import threading import time print("主线程任务开始处理") def task(th_name): print("子线程任务开始处理,参数:{0}".format(th_name)) time.sleep(3) # <-- 这里睡眠了三秒,可以看见主线程继续往下走了 print("子线程任务处理完毕") if __name__ == '__main__': # ==== 实例化出Thread类并添加子线程任务以及参数 ==== t1 = threading.Thread(target=task, args=("线程[1]",)) # <-- 参数必须添加逗号。因为是args所以会打散,如果不加逗号则不能进行打散会抛出异常 t1.start() # 等待CPU调度..请注意这里不是立即执行 print("主线程任务处理完毕") # ==== 执行结果 ==== """ 主线程任务开始处理 子线程任务开始处理,参数:线程[1] 主线程任务处理完毕 子线程任务处理完毕 """
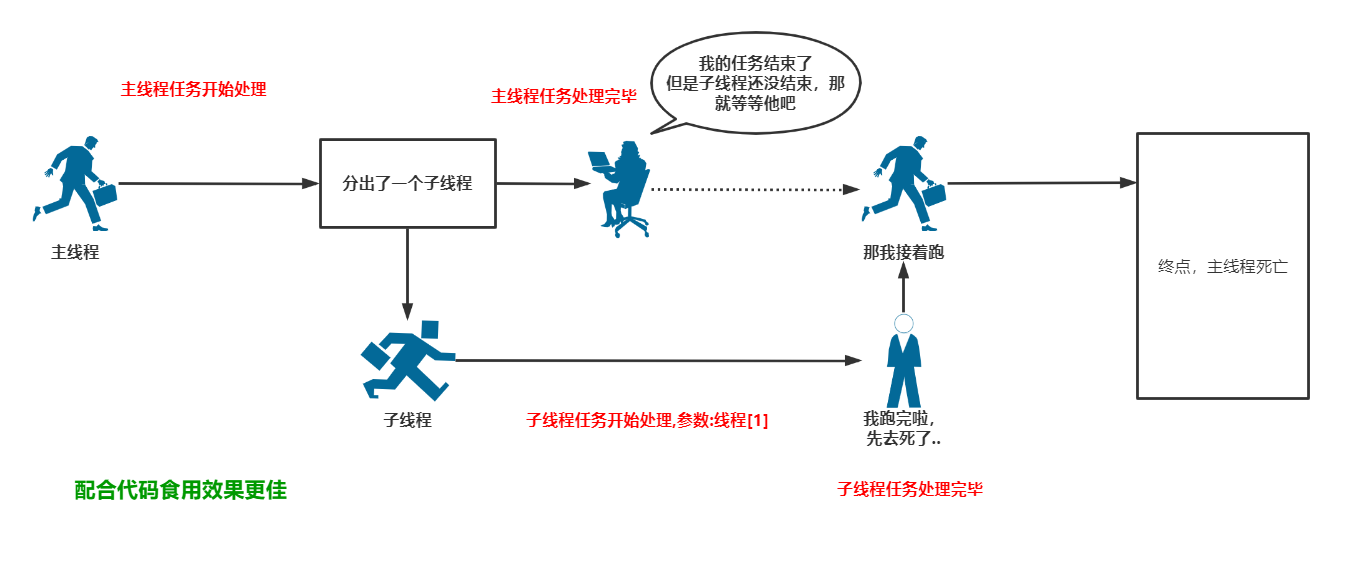
我们可以看见,在进行time.sleep()的时候线程做了一次切换,这是因为该方法是属于IO操作,所以GIL锁将执行权限丢给了主线程。还有一点要注意的就是主线程任务处理完毕后不会立马结束掉,而是等子线程任务处理完毕后才会真正将主线程连同子线程一起kill掉。
图示:
自定义类继承Therad并覆写run方法
这种方法并不常见,但是还是要举例说出来。我们可以看到第一种方法是实例化出了Therad类,并且执行了其start()方法,然后子线程就可以被调度了,其实在内部是通过start()方法调用了Therad类下的run()方法的。
run():代表线程活动的方法。你可以在子类型里重载这个方法。 标准的
那么我们就可以自定义一个类并继承Therad类,再覆写run()方法
import threading import time print("主线程任务开始处理") class Threading(threading.Thread): """自定义类""" def __init__(self, th_name): self.th_name = th_name super(Threading, self).__init__() def run(self): print("子线程任务开始处理,参数:{0}".format(self.th_name)) time.sleep(3) # <-- 这里睡眠了三秒,可以看见主线程继续往下走了 print("子线程任务处理完毕") if __name__ == '__main__': t1 = Threading("线程[1]") t1.start() # 等待CPU调度..请注意这里不是立即执行 print("主线程任务处理完毕") # ==== 执行结果 ==== """ 主线程任务开始处理 子线程任务开始处理,参数:线程[1] 主线程任务处理完毕 子线程任务处理完毕 """
注意现在依然是主线程任务处理完毕后现在是不会立马结束掉的,而是等子线程任务处理完毕后才会真正将主线程kill掉。其实原则上这两种创建线程的方式都一模一样。
源码浅析-选读
这个源码浅析非常浅,主要是来看一下基于实例化Therad类创建子线程内部是如何做的。
那么我们看一下其Thread类的源码,:
class threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, ***, daemon=None)
调用这个构造函数时,必需带有关键字参数。参数如下:
group应该为None;为了日后扩展ThreadGroup类实现而保留。
target是用于
name是线程名称。默认情况下,由 "Thread-N" 格式构成一个唯一的名称,其中 N 是小的十进制数。
args是用于调用目标函数的参数元组。默认是()。
kwargs是用于调用目标函数的关键字参数字典。默认是{}。如果不是
None,daemon 参数将显式地设置该线程是否为守护模式。 如果是None(默认值),线程将继承当前线程的守护模式属性。如果子类型重载了构造函数,它一定要确保在做任何事前,先发起调用基类构造器(
Thread.__init__())。


class Thread: """注释被我删掉了""" _initialized = False # 这是一个状态位,来表示该线程是否被被初始化过 def __init__(self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None): """注释被我删掉了""" assert group is None, "group argument must be None for now" #如果不是 None,daemon参数将显式地设置该线程是否为守护模式。 如果是 None (默认值),线程将继承当前线程的守护模式属性。 if kwargs is None: kwargs = {} # kwargs 是用于调用目标函数的关键字参数字典。默认是 {}。 self._target = target # 对于第一种调用方式来说,它就是我们的task函数。 self._name = str(name or _newname()) # 线程名 self._args = args # _args是用于调用目标函数的参数元组。默认是 ()。 self._kwargs = kwargs if daemon is not None: # 判断其是否为守护线程 self._daemonic = daemon else: self._daemonic = current_thread().daemon self._ident = None # 这个是线程的编号 if _HAVE_THREAD_NATIVE_ID: # 判断是否具有本地ID self._native_id = None self._tstate_lock = None # 锁定的状态 self._started = Event() # 开始 self._is_stopped = False # 状态位,是否停止 self._initialized = True # 将初始化状态为改为True # Copy of sys.stderr used by self._invoke_excepthook() self._stderr = _sys.stderr self._invoke_excepthook = _make_invoke_excepthook() # For debugging and _after_fork() _dangling.add(self)
我们可以看见其__init__方法大多都是做了一些初始化的东西。下面我们来看run()方法,它才是离我们最近的一个方法。
def run(self): """注释被我删掉了""" try: if self._target: # 简单吧,这个方法,就是判断你有没有传入一个函数。即我们定义的task self._target(*self._args, **self._kwargs) # 有的话就立即执行,我们传入的name其实就放在了_args中。这里将它打散出来了,所以我们的task函数中的第一个参数name能收到。 finally: # Avoid a refcycle if the thread is running a function with # an argument that has a member that points to the thread. del self._target, self._args, self._kwargs # 不管处不出错,都会清理他们。当然,如果有则是执行完成后清理
好了,其实看到这里就行了。其实我们自定义类的传参也可以不用覆写__init__再去调用父类方法初始化进行传参,我们完全以另一种方式,但是我个人不太推荐。
import threading import time print("主线程任务开始运行") class Threading(threading.Thread): """自定义类""" def run(self): print(self._args) # ('线程[1]',) print(self._kwargs) # {} print("子线程任务开始处理,参数:{0}".format(self._args[0])) time.sleep(3) # <-- 这里睡眠了三秒,可以看见主线程继续往下走了 print("子线程任务运行完毕") if __name__ == '__main__': t1 = Threading(args=("线程[1]",)) t1.start() # 等待CPU调度..请注意这里不是立即执行 print("主线程任务处理完毕") # ==== 执行结果 ==== """ 主线程任务开始处理 ('线程[1]',) 主线程任务处理完毕 {} 子线程任务开始处理,参数:线程[1] 子线程任务处理完毕 """
threading模块方法大全
| thrading模块方法大全 | |
|---|---|
| 方法/属性名称 | 功能描述 |
| threading.active_count() | 查看当前进程下一共存活了多少个线程的数量,返回的是一个int值。 |
| threading.current_thread() | 获取当前线程对象。 |
| threading.currentThread() | 同上 |
| threading.excepthook(args, /) | 处理由 |
| threading.get_ident() | 返回当前线程对象的编号。 |
| threading.get_native_id() | 返回当前线程对象的编号。和threading.get_ident()相同。 |
| threading.enumerate() | 查看当前进程存活了的所有线程对象,以列表形式返回。 |
| threading.main_thread() | 返回主线程对象。 |
| threading.settrace(func) | 不太清楚..好像是测试用的。 |
| threading.stack_size([size]) | 返回创建线程时使用的堆栈大小。 |
| threading.TIMEOUT_MAX | 规定一个全局的所有阻塞函数的最大时间。 |
线程对象方法大全
| 线程对象方法大全(即Thread类的实例对象) | |
|---|---|
| 方法/属性名称 | 功能描述 |
| start() | 启动线程,该方法不会立即执行,而是告诉CPU自己准备好了,可以随时调度,而非立即启动。 |
| run() | 一般是自定义类继承Thread并覆写的方法,即线程的详细任务逻辑。 |
| join(timeout=None) | 主线程默认会等待子线程运行结束后再继续执行,timeout为等待的秒数,如不设置该参数则一直等待。 |
| name | 可以通过 = 给该线程设置一个通俗的名字。如直接使用该属性则返回该线程的默认名字。 |
| getName() | 获取该线程的名字。 |
| setName() | 设置该线程的名字。 |
| ident | 获取线程的编号。 |
| native_id | 获取线程的编号,和ident相同。 |
| is_alive() | 查看线程是否存活,返回布尔值。 |
| isAlive( ) | 同上,但是不推荐使用这种方法。 |
| daemon | 查看线程是否为一个守护线程,返回布尔值。默认为False。 |
| isDaemon() | 查看线程是否为一个守护线程,返回布尔值。默认为False。 |
| setDaemon() |
设置一个线程为守护线程,参数如果为
|
常用方法示例
由于方法太多了,所以这里就只例举一些非常常用的。
守护线程setDaemon()
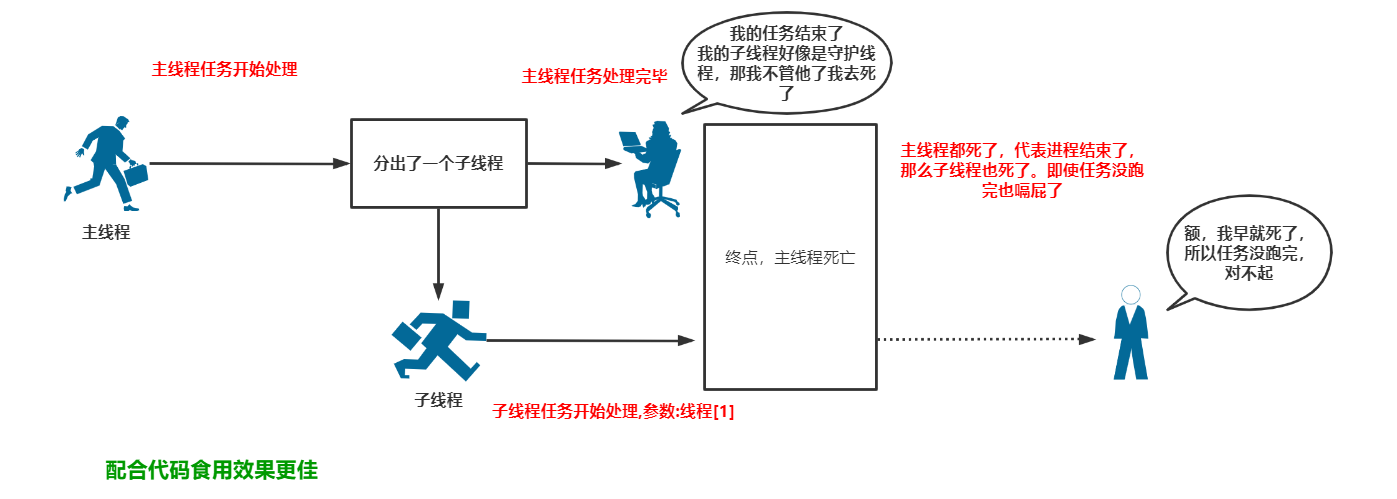
setDaemon():设置一个线程为守护线程,参数如果为True则表示该线程被设置为守护线程,默认为False。当主线程运行完毕之后设置为守护线程的子线程便立即结束执行...
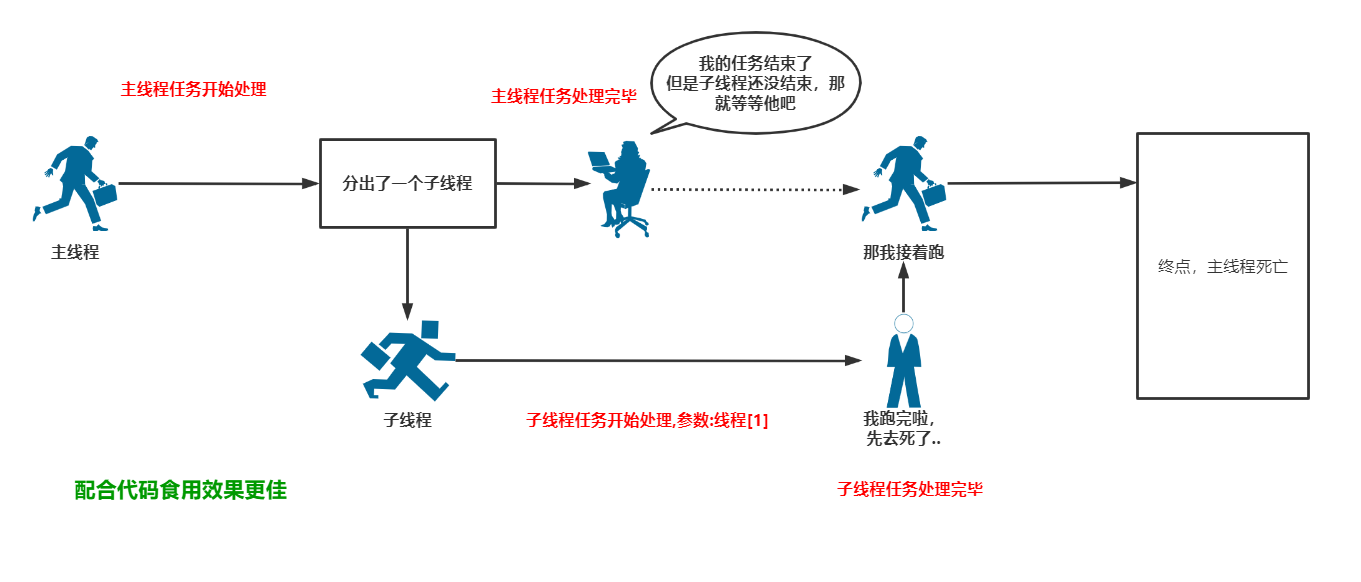
我们对比上面的图,现在子线程是没有设置为守护线程的:
当他设置为守护线程之后会是这样的:
代码如下:
import threading import time print("主线程任务开始处理") def task(th_name): print("子线程任务开始处理,参数:{0}".format(th_name)) time.sleep(3) print("子线程任务处理完毕") if __name__ == '__main__': t1 = threading.Thread(target=task, args=("线程[1]",)) t1.setDaemon(True) # <-- 设置线程对象t1为守护线程,注意这一步一定要放在start之前。 t1.start() # 等待CPU调度..请注意这里不是立即执行 print("主线程任务处理完毕") # ==== 执行结果 ==== """ 主线程任务开始处理 子线程任务开始处理,参数:线程[1] 主线程任务处理完毕 """
线程阻塞join()
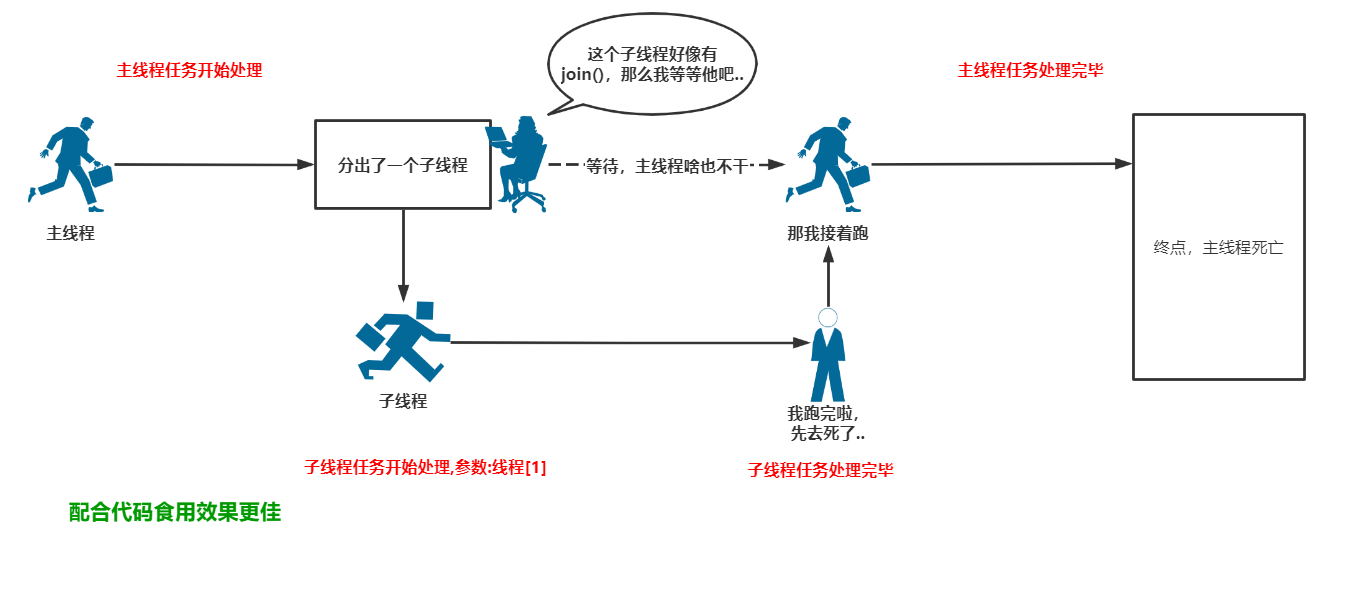
join(timeout=None):主线程默认会等待子线程运行结束后再继续执行,timeout为等待的秒数,如不设置该参数则一直等待。
图示如下:(未设置超时时间)
代码如下:
import threading import time print("主线程任务开始处理") def task(th_name): print("子线程任务开始处理,参数:{0}".format(th_name)) time.sleep(3) print("子线程任务处理完毕") if __name__ == '__main__': t1 = threading.Thread(target=task,args=("线程[1]",)) t1.start() # 等待CPU调度..请注意这里不是立即执行 t1.join() # <--- 放在start()下面,死等 print("主线程任务处理完毕") # ==== 执行结果 ==== """ 主线程任务开始处理 子线程任务开始处理,参数:线程[1] 子线程任务处理完毕 主线程任务处理完毕 """
图示如下:(设置超时时间)
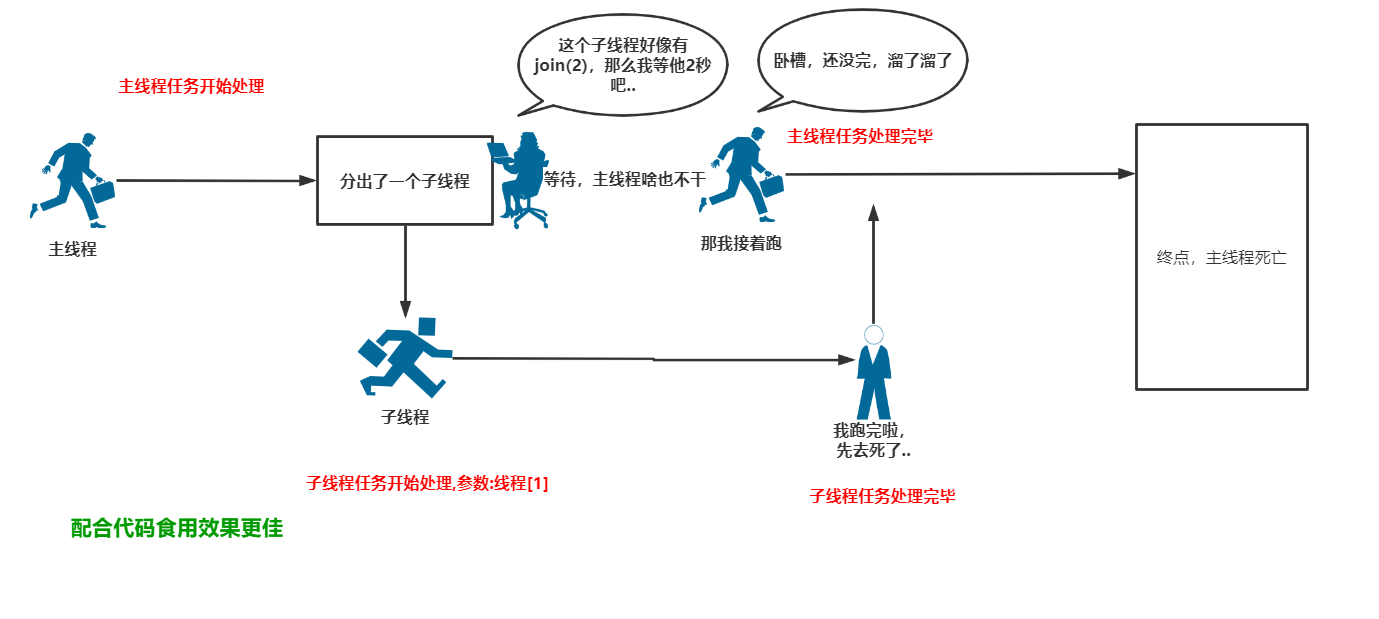
代码如下:
import threading import time print("主线程任务开始处理") def task(th_name): print("子线程任务开始处理,参数:{0}".format(th_name)) time.sleep(3) print("子线程任务处理完毕") if __name__ == '__main__': t1 = threading.Thread(target=task,args=("线程[1]",)) t1.start() # 等待CPU调度..请注意这里不是立即执行 t1.join(2) # <--- 放在start()下面,等2秒后主线程继续执行 print("主线程任务处理完毕") # ==== 执行结果 ==== """ 主线程任务开始处理 子线程任务开始处理,参数:线程[1] 主线程任务处理完毕 子线程任务处理完毕 """
注意,join()方法可以多次设置!
join()与setDaemon(True)共存
如果同时设置
setDaemon(True)与join()方法会怎么样呢?有两种情况:1.
join()方法没有设置timeout(没有设置即表示死等)或者timeout的时间比子线程作业时间要长,这代表子线程会死在主线程之前,setDaemon(True)也就没有了意义,即失效了。2.
join()设置了timeout并且timeout的时间比子线程作业时间要短,这代表主线程会死在子线程之前,setDaemon(True)生效,子线程会跟着主线程一起死亡。
# ==== 情况一 ==== import threading import time print("主线程任务开始处理") def task(th_name): print("子线程任务开始处理,参数:{0}".format(th_name)) time.sleep(3) print("子线程任务处理完毕") if __name__ == '__main__': t1 = threading.Thread(target=task,args=("线程[1]",)) t1.setDaemon(True) # <--- 放在start()上面,主线程运行完后会立即终止子线程的运行。但是由于有join(),故不生效。 t1.start() # 等待CPU调度..请注意这里不是立即执行 t1.join() # <--- 放在start()下面,等2秒后主线程继续执行 print("主线程任务处理完毕") # ==== 执行结果 ==== """ 主线程任务开始处理 子线程任务开始处理,参数:线程[1] 子线程任务处理完毕 主线程任务处理完毕 """
# ==== 情况二 ==== import threading import time print("主线程任务开始处理") def task(th_name): print("子线程任务开始处理,参数:{0}".format(th_name)) time.sleep(3) print("子线程任务处理完毕") if __name__ == '__main__': t1 = threading.Thread(target=task,args=("线程[1]",)) t1.setDaemon(True) # <--- 放在start()上面,主线程运行完后会立即终止子线程的运行。但是由于有join(),故不生效。 t1.start() # 等待CPU调度..请注意这里不是立即执行 t1.join(2) # <--- 放在start()下面,等2秒后主线程继续执行 print("主线程任务处理完毕") # ==== 执行结果 ==== """ 主线程任务开始处理 子线程任务开始处理,参数:线程[1] 主线程任务处理完毕 """
设置与获取线程名
我们来看一下如何设置与获取线程名。
threading.current_thread():获取当前线程对象。
getName():获取该线程的名字。
setName():设置该线程的名字。
name:可以通过=给该线程设置一个通俗的名字。如直接使用该属性则返回该线程的默认名字。
import threading import time print("主线程任务开始处理") def task(th_name): print("子线程任务开始处理,参数:{0}".format(th_name)) obj = threading.current_thread() # 获取当前线程对象 print("获取当前的线程名:{0}".format(obj.getName())) print("开始设置线程名") obj.setName("yyy") print("获取修改后的线程名:{0}".format(obj.getName())) time.sleep(3) # <-- 这里睡眠了三秒,可以看见主线程继续往下走了 print("子线程任务处理完毕") if __name__ == '__main__': # ==== 第一步:实例化出Thread类并添加子线程任务以及参数 ==== t1 = threading.Thread(target=task, args=("线程[1]",),name="xxx") # 可以在这里设置,如果不设置则为默认格式:Thread-1 数字是按照线程个数来定的 t1.start() # 等待CPU调度..请注意这里不是立即执行 print("主线程名:",threading.current_thread().name) # 直接使用属性 name print("主线程任务处理完毕") # ==== 执行结果 ==== """ 主线程任务开始处理 子线程任务开始处理,参数:线程[1] 获取当前的线程名:xxx 开始设置线程名 获取修改后的线程名:yyy 主线程名: MainThread 主线程任务处理完毕 子线程任务处理完毕 """
多线程的应用场景
由于GIL锁的存在,Python中对于I/O操作来说可以使用多线程编程,如果是计算密集型的操作则不应该使用多线程进行处理,因为没有I/O操作就不能通过I/O切换来执行其他线程,故对于计算密集型的操作来说多线程没有什么优势。甚至还可能比普通串行还慢(因为涉及到线程切换,虽然是毫秒级别,但是计算的数值越大这个切换也就越密集,GIL锁是100个CPU指令切换一次的)
注意:我们是在Python2版本下进行此次测试,Python3版本确实相差不大,但是,从本质上来说依然是这样的。
import threading import time num = 0 def add(): global num for i in range(10000000): # 一千万次 num += 1 def sub(): global num for i in range(10000000): # 一千万次 num -= 1 if __name__ == '__main__': start_time = time.time() add() sub() end_time = time.time() print("执行时间:",end_time - start_time) # ==== 执行结果 ==== 三次采集 """ 大约在 1.3 - 1.4 秒 """
# coding:utf-8 import threading import time num = 0 def add(): global num for i in range(10000000): # 一千万次 num += 1 def sub(): global num for i in range(10000000): # 一千万次 num -= 1 if __name__ == '__main__': start_time = time.time() t1 = threading.Thread(target=add,) t2 = threading.Thread(target=sub,) t1.start() t2.start() t1.join() t2.join() end_time = time.time() print(u"执行时间:",end_time - start_time) # ==== 执行结果 ==== 三次采集 """ 大约 4 - 5 秒 """
补充:Timer线程延迟启动
import threading def task(): print(threading.current_thread().getName(),end="") print("启动了...") if __name__ == '__main__': t1 = threading.Timer(3,task) t2 = threading.Timer(3,task) t1.start() # 线程任务三秒后准备就绪,可以被CPU调度执行。 t2.start() # ==== 执行结果 ==== """ Thread-1启动了... Thread-2启动了... """

